文档资源库建设,搜索引擎如何搜索文件的内容?
我们之前有几篇文章,介绍了如何构建资源库以及电子文档数据库,《图书馆多媒体电子资源库建设方案》《文化遗产数据库建设方案》,那么在建设文档资源库或者电子资源库中,如何检索文件中的内容,变成了一个重要的问题。

搜索的本质
搜索,其实本质上是查字典。
所以,程序搜索和字典也是一样,通常情况下,要建立字典目录,也就是索引。
于是,步骤便是:1 分词、2 索引、3 检索。
但是文件的内容,我们该如何搜索?
其实本质上是一样,我们的流程是分词、索引、检索,相当于加工->存储->搜索,如果要搜索文档中内容,我们要做的只是在加工层面,将文档的内容提取出来,然后进行分词、索引、检索即可。
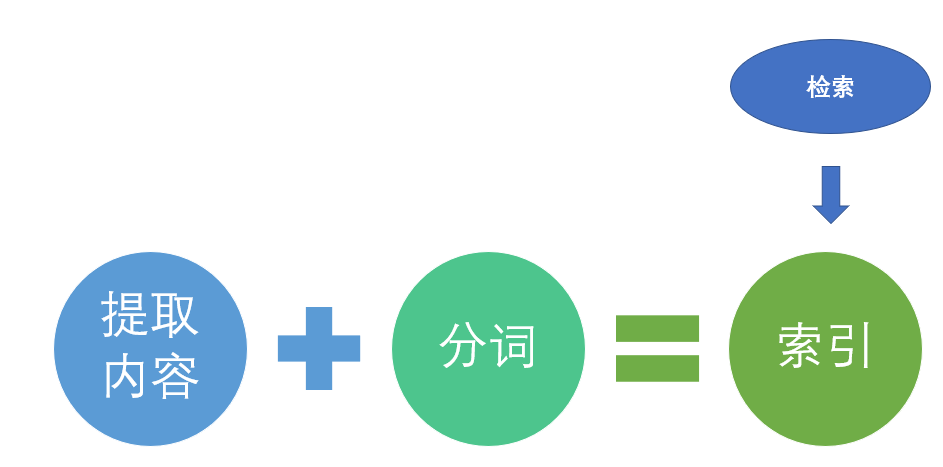
文档内容的提取
那么首先,我们就要进行文件提取,我们这里列举一下常见文件提取工具,
(1)Apache Tika APP
(2)Apache Tika Server
(3)The Solr built-in extractor
(4)pdftotext for pdfs
(5)python pdf2text for pdfs
(6)golang docconv
上面的几个,都是常见的文档提取工具,我们就不做更深入的研究,如果要使用,大家Google一下,然后将对应的命令安装上就可以。
最终是通过Web调用这些命令,然后将文档的内容提取出来,给分词程序进行分词,然后索引加工。
检索文档内容
一旦索引入库了,那么就没有什么其他难点了,跟其他普通的检索程序一样,将对应的字段的内容,按照用户输入进行检索。下图是一个Search API的架构,后台的扩展性,解释了如何架构一个灵活的搜索引擎。
文档索引
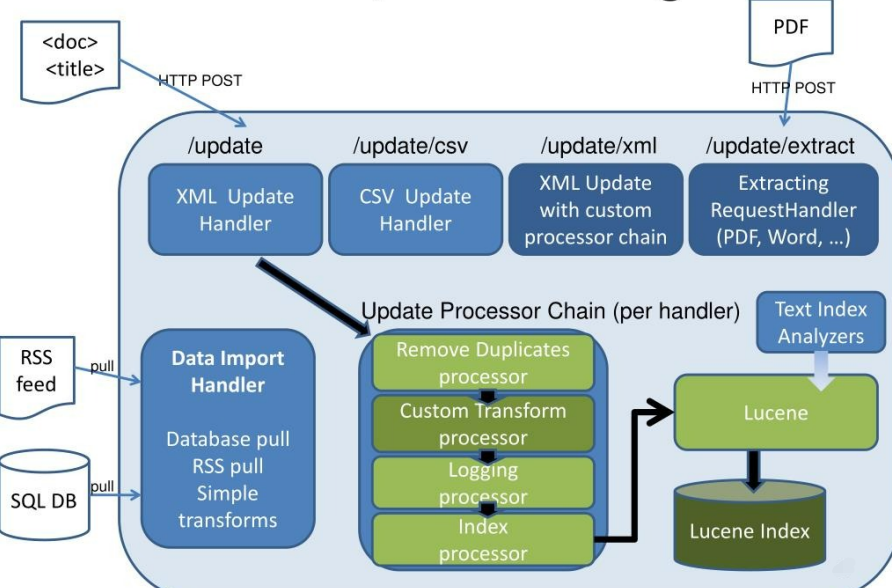
文档图片索引
如何通过开源的解决方案
我们采用开源的Drupal来构建文档数据库/电子资源数据库,其实Drupal本身自带了很多模块,能够自动完成将文档里面的数据提取出来,然后导入索引库,因此这些工作其实不用我们自己开发,推荐的模块如下:
- Search API Attachement
https://www.drupal.org/project/search_api_attachments - File Extractor
https://www.drupal.org/project/file_extractor
具体的工作原理跟我们上面讲的是一样,因此原理都是相通的,只是模块直接帮我们处理了很多细碎的工作,比较比较方便使用,此外也是经过了很多改进以及Bug修复,相对来说,比较稳定。
此外,可以参考附件的Solr架构介绍的PDF文件,可以了解Solr更多的细节介绍。
更多方案介绍,可以参考我们的《文化数据库方案介绍》
更多技术资料,可以参考我们之前相关介绍文章,如果需要建设相关数据库,以及Drupal灵活的元数据/检索/可视化构建演示或者资料,可以联系我们。
6、文档资源库建设之搜索引擎如何搜索文件的内容(pdf/wrod)?
9、Headless CMS:以API为输出的内容系统的构建
 QQ交谈客服1
QQ交谈客服1

