基于CMS的私有知识库与公共人工智能的集成
人工智能可以说是未来10年的一个趋势和风口,其中OpenAI是首先推出的一种人工智能技术驱动的自然语言处理工具,它基于Transformer神经网络架构,这是一种用于处理序列数据的模型,拥有语言理解和文本生成能力,可以不断学习和升级,不仅仅是传统的检索功能。
人工智能的出现,对很多行业,很多产业,很多应用都是颠覆性的改革。
其中对于科研、教学、图书馆领域内,通过人工智能工具,提炼和学习现有知识,学习私有领域的知识,然后叠加AI本身的知识,可以实现更高级更专业的人工智能机器人、生成新的学习素材。
本文就如何训练一个私有化的ChatGPT人工智能模型做一个简单介绍,类似于训练一个专业领域的人工智能机器人。

训练私有化ChatGPT的方法
目前根据ChatGPT的官网文档,有两类方式训练自己的ChatGPT
1. Embeddings
2. Finetune
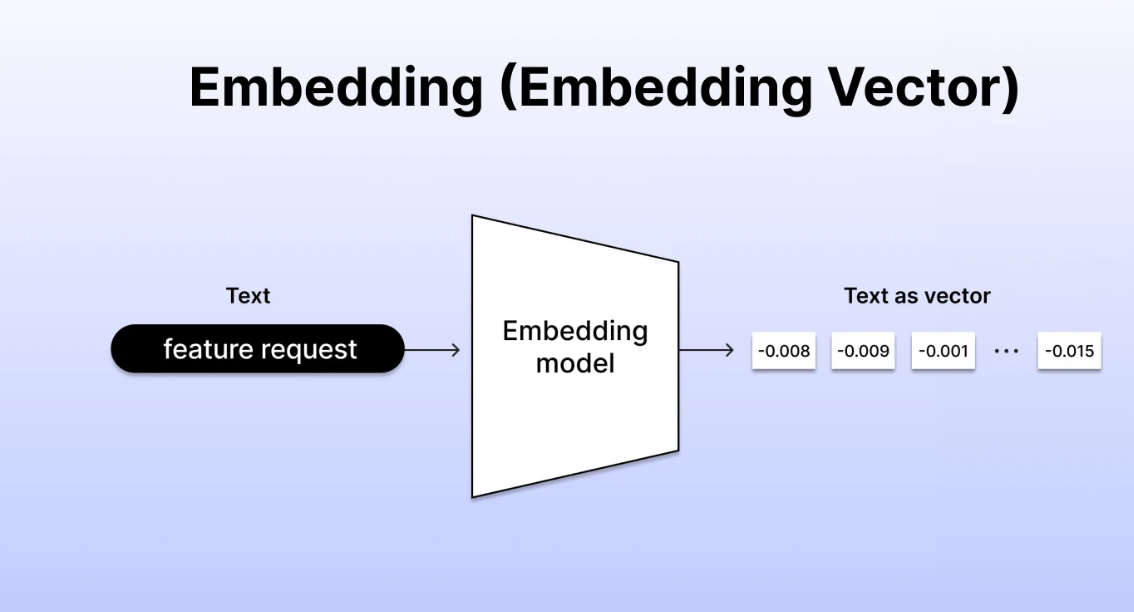
第一个Embeddings,类似于联合查询,将自有的数据进行向量化存储,通过OpenAI和Embedding的向量数据进行联合查询。
第二个Finetune,类似于私有化一个自定义的模型,这个模型进行投喂了大量的私有数据,所以AI就会比较专业的进行回答相关问题。
Embeddings,
主要功能是通过OpenAI的Embedding生成接口,来将本地的数据生成向量数据,为什么要用OpenAI的embeddings接口呢?
因为OpenAI通过人工智能的方式,生成的向量数据更加准确,所以Embeddings的方式主要是接口生成的向量数据,然后可以将这些向量数据保存到本地的向量数据库,比如MongoDB等等,然后通过向量查询获取自己想要的结果。
具体可以参考youtube这个介绍:
https://www.youtube.com/watch?v=ySus5ZS0b94
当然,还有另外一种应用,是在上面的步骤上增加一个OpenAI API接口的调用。
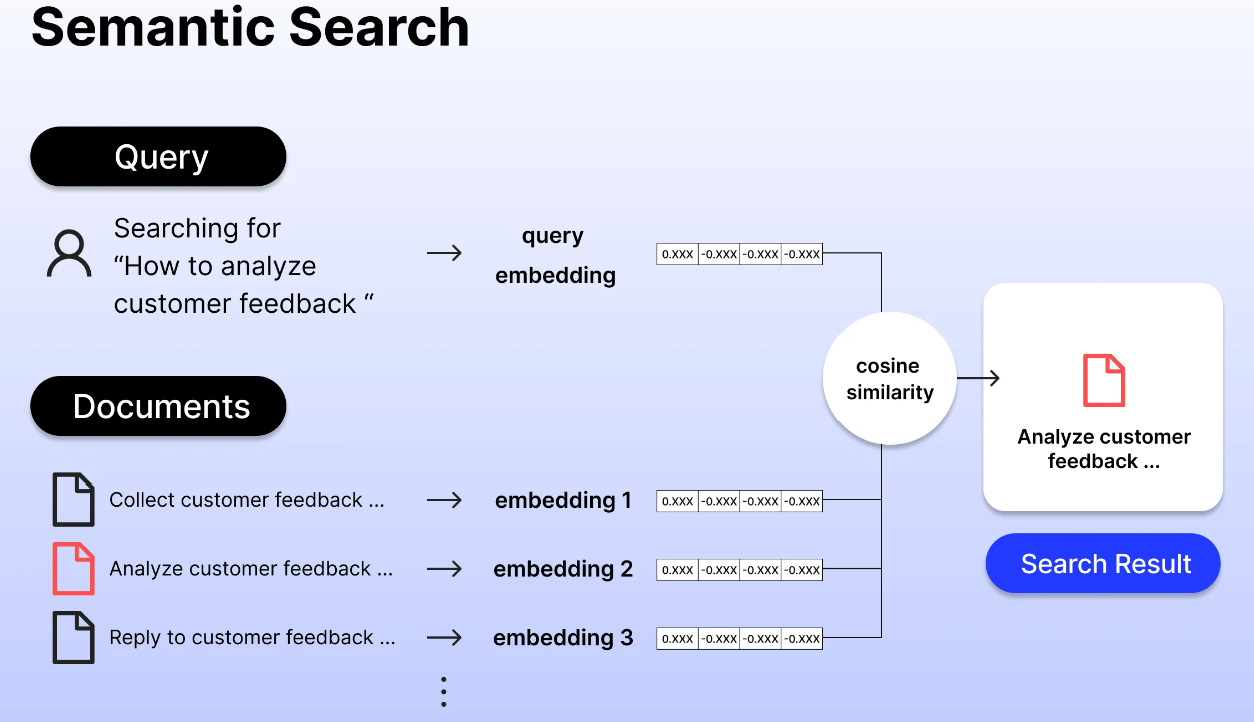
1. 生成Embeddings,存储向量
2. 用户搜索,通过input搜索向量,将搜到的结果发送给ChatGPT,让ChatGPT根据输入的内容进行回答
最终生成的prompt类似下面结构:
请用下面的文章来回答如下问题,
文章摘要:xxxx
文章摘要:xxx
...
问题:请问xxxx
具体的代码可以参考这篇文章介绍:
https://cookbook.openai.com/examples/question_answering_using_embeddings

Finetune
Finetune是一种类似于对模型的优化,他是长期的持续的,对于大量数据或者对于某个特定领域的综合知识可以采用这种方式。
Finetune一旦完成,那么后续就是可以持续的调用这模型获取答案,所以后续的prompt就无需再给ChatGPT更多的提示和样例参考。
Finetune可以有下面几步:
1. 准备数据
2. 训练一个模型
3. 评估训练结果,可以不断重复步骤2
4. 使用训练好的模型
需要注意的是FineTune的模型会是私有的,比如my_modal,另外一个是上传的数据是有大小限制的,目前最大1GB限制。
1. 数据格式的要求参考
https://cookbook.openai.com/examples/chat_finetuning_data_prep
2. OpenAI可视化操作界面:
https://platform.openai.com/finetune
3. 具体可以参考OpenAI的官方文档
https://platform.openai.com/docs/guides/fine-tuning
私有化Embeddings和Finetune的区别
私有化Embeddings和Finetune有什么区别呢?
目前来看主要是应用场景不同,Embedding主要偏向更加准确的结果,精准的结果,并且时效性短,不需要长时间记忆,另外,更多配合向量数据库查询,应用于更垂直的领域。
而对于Finetune来说,其答案更加通用性,常识性,为一般应用目的,给其投喂数据的主要目的是弥补其知识面不足,增加更多物料。
主要应用场景如下:
1. 答案检索
2. 内容分类
3. 相关推荐
4. 异常检测
而Finetune的应用场景主要表现在如下几个方面:
1. 新建一个新的回答风格、方式
2. 对于原有模型的内容提升、内容纠错
3. 处理更多边缘性问题
可以看OpenAI这篇讨论 https://community.openai.com/t/fine-tuning-vs-embedding/35813/10
可以参考Youtube的这个介绍
https://www.youtube.com/watch?v=_wtfszFzqt0
后记
不管是那种数据投喂方式,最终都需要数据的准备,所以CMS的内容管理系统在此刻发挥了重要作用,如果在具备原始数据的情况下,训练一个自定义个ChatGPT模型那么将是非常快速和高效的。
因此,ChatGPT与内容管理的最终整合,能够将AI应用到具体的数据应用层面,发挥更高作用。
创作不易,转载请注明出处!
更多Drupal CMS相关内容,请参考我们其他相关文章,
7、如何通过Drupal Rector来快速升级Drupal
 QQ交谈客服1
QQ交谈客服1

